Abstract
This project is an attempt to study well established methods of author attribution in the context of Hindi Literature. While sophisticated approaches to author attribution have been tested in English, the terrain of Indian languages remains untouched. This is partly because of the morphologically rich structure of the languages and partly because of the absence of an authoritative dataset in Hindi. Our project explorers supervised and unsupervised methods of author attribution in Hindi Literature. The differences in accuracy in results can be related to variance in effectiveness of the common stylistic features in indicating identity of the author. These could vary uniformly from Hindi to English Texts and this project tries to find such differences.
Corpus
One of the most vital component of our project was a high quality dataset preferably in Unicode. Unfortunately, none of the datasets that we came across met our requirements, hence we decide to build a corpus of Hindi Literature by ourselves.
The data source of our corpus if www.hindisamay.com, which allows all of its content to be downloaded in doc format. For the data to be useful, we had to convert it into text format using LibreOffice in headless mode. The created corpus consists of novels from the following authors: Rabindranath Tagore, Vibhuti Narayan, Premchand, Sarat Chandra Chattopadhyay and Dhamarvir Bharati. (Note: due to the lack of hindi novels by Rabindranath Tagore, we had to resort to using short stories written by him.)
Methodology
Preprocessing
The documents were normalized by removing all Hindi punctuations. To vectorize the authors, we concatenated the work of each author and divided them into snippets of 500 words each.
Feature Vector Formation
Unigram
For Unigram analysis, the top 4500 frequent words were used to create a Bag of Words model for each vector created in the pre-processing stage.
Bigram and Trigram Analysis
For the other ngram analysis, the top 2000 frequent ngrams were used to create a Bag of Words model for each vector created in the pre-processing stage.
Multiple Discriminant Analysis
For MDA, we only considered the top 1000 frequency bigrams and top 1000 frequent trigrams which were concatenated in order to create feature vectors.
Dimensionality Reduction using PCA
The high dimensional vectors obtained from the feature vector creation stage were reduced to manageable dimensions, using Principal Component Analysis. This ensured optimum usage of time in the later stages. The following caveats are in order:
Unigram analysis was done the raw feature vectors. This decision was undertaken because, Unigram merely served to eliminate the authors whose works were translated by multiple translators (Rabindranath Tagore in our case).
Results have been reported for the top 20 dimensions, albeit analysis was carried out for 5, 10 and 40 dimensions. It was seen that the results remained fairly static until 20 dimensions.
Classification
Support Vector Machine Classification
We trained an SVM for each of the author separately using the Radial Basis Kernel Function.
K-Means Clustering
The dimensionally reduced feature vectors were clustered using K-Means clustering with the number of clusters set to four. The cluster containing maximum number from a particular author was assumed to be that author’s cluster.
Multivariate Discriminant Analysis
As an attempt to improve results further, two features - word bigrams and trigrams - were combined together and then clustered using K-Means clustering.
Evaluation
Supervised Learning
A test set for each author was kept (such that training:test snippets were in a 5:2 ratio). Evaluation on each one v/s all classifier was done separately and the results were tabulated.
Unsupervised Learning
The cluster with the most snippets actually labelled as written by author A was assigned A. After the assignment of clusters to authors, the misclassfication was computed using the groundtruth. Using these values, various statistics for each clustering was computed.
Results
| Author | Precision | Recall | F-score |
|---|---|---|---|
| Premchand | 0.9325 | 0.9651 | 0.9485 |
| Sarat | 0.9643 | 0.9356 | 0.9497 |
| Vibhuti | 0.9933 | 0.8268 | 0.9024 |
| Dharamvir | 1.0 | 0.64 | 0.7805 |
| Author | Precision | Recall | F-score |
|---|---|---|---|
| Premchand | 0.9939 | 0.9894 | 0.9916 |
| Sarat | 0.9982 | 0.9544 | 0.9758 |
| Vibhuti | 0.8764 | 0.9916 | 0.9304 |
| Dharamvir | 0.9906 | 0.848 | 0.9137 |
| Author | Precision | Recall | F-score |
|---|---|---|---|
| Premchand | 0.9969 | 0.9878 | 0.9923 |
| Sarat | 0.9935 | 0.8732 | 0.9295 |
| Vibhuti | 0.9464 | 0.9958 | 0.9705 |
| Dharamvir | 0.7151 | 0.904 | 0.7985 |
Clusters
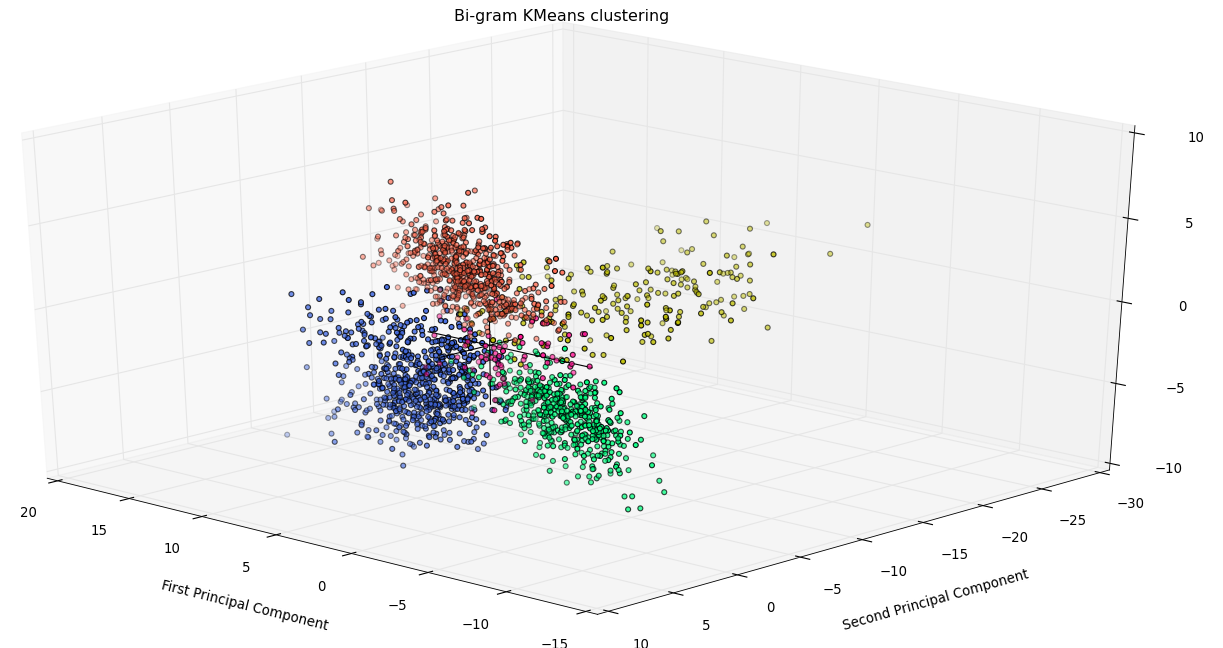
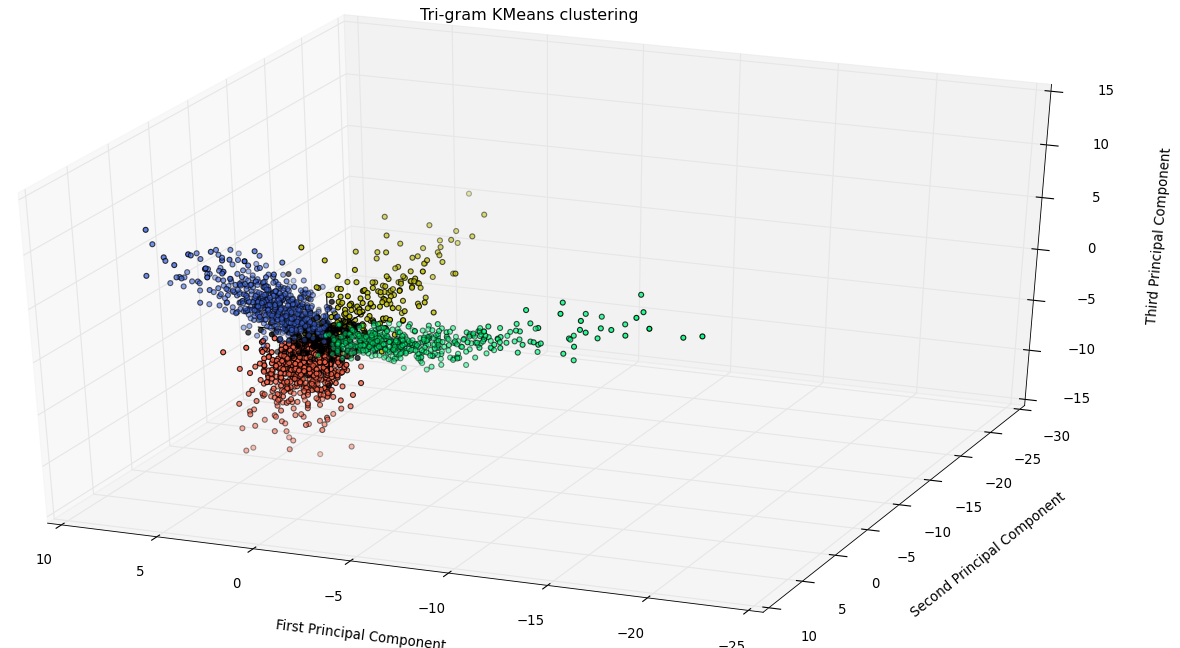
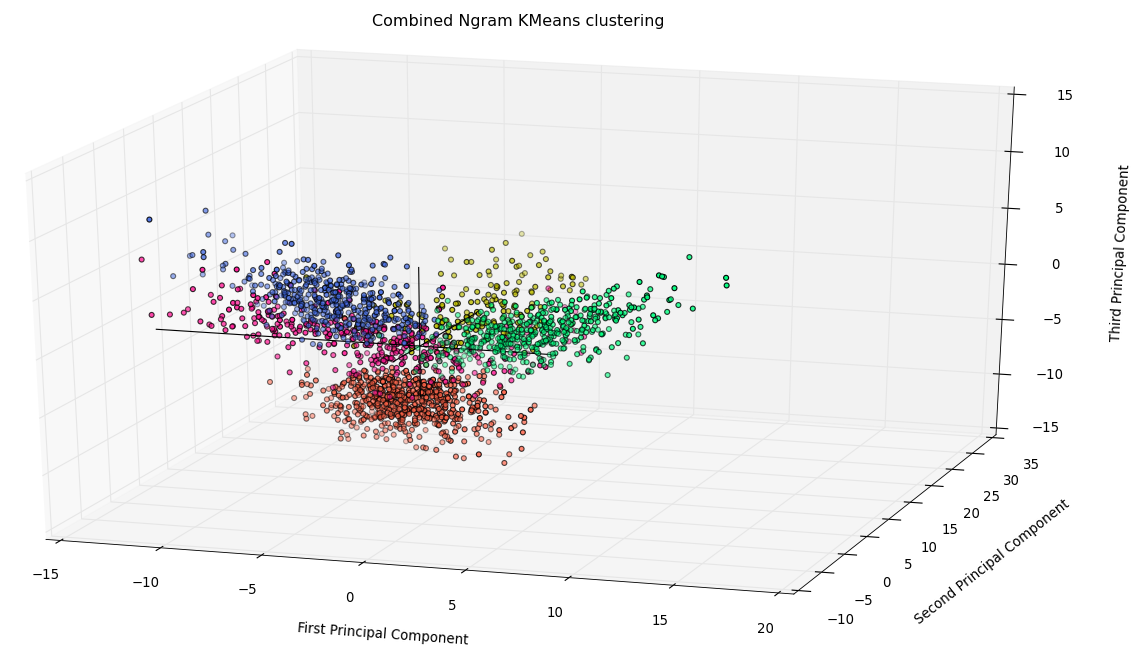
Insights
Since works of Rabindranath Tagore were translations, their removal from the analysis improved the results since the multiple translators made his work heterogeneous. (The fact that most of his collected works were translations is bolstered by the results Unigram Analysis.)
The corpus contained many essays by Vibhuti Narayan Rai. Ergo, his works included many domain specific content words, leading to good results.
The Corpus contained only novels for Premchand and so both recall and precision for him were high > 70%
The increase in number of classes (authors) will gradually lead to reduction in accuracy of the results as the amount of distinction in the feature vector space will be too less for spherical clusters to be found.
The sparsity of the trigram vectors led to a lower F-score for it compared to Bigrams. This indicates that a larger dataset will result in better Precision and Recall for trigrams.
MDA did not prove to be too beneficial as the F-score for both features individually was already saturated at more than 90-95%. Thus, the application of MDA did not improve our study very substantially.
Conclusion
Our analysis has given us valuable insights on the nature of and on the viability of using standard methods on Indian Literature datasets for Authorship Attribution. Further work on Authorship Attribution in Indian Language datasets can be pursued by augmenting the dataset we have constructed and by running the methods we have used on it. Since unsupervised methods have also proven to work well in our analysis, our approach could work even if the ground truth of authorship is not known. This could greatly benefit people working on plagiarism detection and literary analysts who want to study writing style of Hindi Authors.
Resources
-
The code used in this project can be viewed at GitHub.
References
- Computational methods in authorship attribution, Koppel, Moshe and Schler, Jonathan and Argamon, Shlomo (2009)
- Authorship attribution in the wild Koppel, Moshe and Schler, Jonathan and Argamon, Shlomo (2011)
- A survey of modern authorship attribution methods Stamatatos, Efstathios (2009)